1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
|
> 我有座 lab 資料庫資訊需要請你調查
他的連線方式是 sql -p lab-vm151-oracle19c-pollo
▸ Thought for 1s, 357 tokens
Investigating Database Connection
I will run a command to locate the sql executable on the system and see if it is available.
● Bash(which sql) (ctrl+o to expand)
I will check the help output of the sql command to understand its syntax and options.
● Bash(sql -h) (ctrl+o to expand)
I will test the database connection using the profile lab-vm151-oracle19c-pollo by running a simple query select 1 from dual; piped into the sql
command.
● Bash(echo "select 1 from dual;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will query the database to list the tables in the current user schema.
● Bash(echo "select table_name from user_tables;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will check the current user and database name to understand the connection context.
● Bash(echo "select user, sys_context('userenv', 'db_name') as db_name, sys_context('userenv', 'con_name') as container_name from dual...) (ctrl+o to
expand)
▸ Thought for 1s, 339 tokens
Investigating Table Ownership
I will search for non-AWR/non-system tables in the POLLO schema by excluding tables starting with WRH or WRM .
● Bash(echo "select table_name from user_tables where table_name not like 'WRH$%' and table_name not like 'WRM$%' order by table_name;...) (ctrl+o to
expand)
I will list the tables that do not start with WR to see the actual dataset tables.
● Bash(echo "select table_name from user_tables where table_name not like 'WR%' order by table_name;" | sql -p lab-vm151-oracle19c-pol...) (ctrl+o to
expand)
I will check the number of rows for each of these tables.
● Bash(echo "select table_name, num_rows from user_tables where table_name not like 'WR%' order by table_name;" | sql -p lab-vm151-ora...) (ctrl+o to
expand)
▸ Thought for 2s, 860 tokens
Analyzing Table Sizes
I will export the schema details of these 7 custom tables to a CSV file called schema.csv using the -o output flag, so we can examine the full
structure of the columns and data types.
● Bash(echo "select table_name, column_name, data_type, data_length from user_tab_columns where table_name in ('ANIME_DATASET_2023', '...) (ctrl+o to
expand)
I will view the schema.csv file to check the schema of the custom tables.
I will list the contents of the /home/gemini directory to see if any CSV file was generated or if it went somewhere else.
● ListDir(/home/gemini) (ctrl+o to expand)
▸ Thought for 2s, 812 tokens
Investigating CSV Export
I will try running the query again, explicitly specifying the format as csv and the absolute output path /home/gemini/schema.csv .
● Bash(echo "select table_name, column_name, data_type, data_length from user_tab_columns where table_name in ('ANIME_DATASET_2023', '...) (ctrl+o to
expand)
▸ Thought for 2s, 524 tokens
Investigating Output Behavior
I will try running the query with the -to_page 6 flag to fetch all 6 pages of the schema information.
● Bash(echo "select table_name, column_name, data_type, data_length from user_tab_columns where table_name in ('ANIME_DATASET_2023', '...) (ctrl+o to
expand)
I will query the number of columns in each table to see how to best retrieve the schema details.
● Bash(echo "select table_name, count(*) from user_tab_columns where table_name in ('ANIME_DATASET_2023', 'ANIME_FILTERED', 'FINAL_ANI...) (ctrl+o to
expand)
I will try using the cached SQL ID bfb3c0f1 along with the -o schema.csv flag to export the schema query results.
● Bash(sql -p lab-vm151-oracle19c-pollo -sql_id bfb3c0f1 -o schema.csv) (ctrl+o to expand)
I will try running the cached query for page 2 to see if we can retrieve subsequent pages using the -page flag.
● Bash(sql -p lab-vm151-oracle19c-pollo -sql_id bfb3c0f1 -page 2) (ctrl+o to expand)
I will check if python3 is available on the system to help automate the extraction of the entire schema.
● Bash(python3 --version) (ctrl+o to expand)
I will test if specifying the -format csv option formats the stdout output as CSV.
● Bash(sql -p lab-vm151-oracle19c-pollo -sql_id bfb3c0f1 -format csv) (ctrl+o to expand)
▸ Thought for 3s, 825 tokens
Analyzing the Export Function
I will write a python script in our scratch directory to execute database queries, auto-detect the number of pages, fetch all pages, and parse the
table output. This will make it easy to dump query results.
● Create(/home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/scratch/query.py) (ctrl+o to expand)
I will run the query tool script to generate the complete schema for the 7 custom tables and output it as a markdown table.
● Bash(python3 /home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/scratch/query.py lab-vm151-oracle19c-po...) (ctrl+o to
expand)
I will view the schema_all.md file containing the custom tables' schema.
● Read(/home/gemini/schema_all.md) (ctrl+o to expand)
▸ Thought for 2s, 931 tokens
Analyzing the Regex Failure
I will edit the Python script to ensure that a semicolon and newline are appended to the query, so that sql-console recognizes and executes it
correctly.
● Edit(/home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/scratch/query.py) (ctrl+o to expand)
I will run the query command again with the updated script.
● Bash(python3 /home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/scratch/query.py lab-vm151-oracle19c-po...) (ctrl+o to
expand)
I will view the generated schema_all.md file.
● Read(/home/gemini/schema_all.md) (ctrl+o to expand)
I will query the database to see if there are any other schema objects, such as views, materialized views, or indexes.
● Bash(echo "select 'views' as obj_type, count(*) as count from user_views union all select 'materialized views' as obj_type, count(*)...) (ctrl+o to
expand)
I will query the indexes associated with our custom tables to see what indexing is defined.
● Bash(echo "select index_name, table_name, uniqueness, status from user_indexes where table_name in ('ANIME_DATASET_2023', 'ANIME_FIL...) (ctrl+o to
expand)
I will query the columns used in these indexes to understand their primary keys and structure.
● Bash(echo "select index_name, table_name, column_name from user_ind_columns where table_name in ('ANIME_DATASET_2023', 'ANIME_FILTER...) (ctrl+o to
expand)
▸ Thought for 13s, 572 tokens
Identifying Key Indexes
I will check the constraints defined on these custom tables to see if they have primary keys, foreign keys, or other constraints.
● Bash(echo "select constraint_name, constraint_type, table_name, status from user_constraints where table_name in ('ANIME_DATASET_202...) (ctrl+o to
expand)
I will wait for the background command to finish and provide its output.
I will query the database to find the physical size (in megabytes) of these tables and their indexes.
● Bash(echo "select segment_name, segment_type, bytes/1024/1024 as size_mb from user_segments where segment_name in ('ANIME_DATASET_20...) (ctrl+o to
expand)
I will check the sizes of any LOB segments stored in the schema to ensure we account for all large objects.
● Bash(echo "select segment_name, bytes/1024/1024 as size_mb from user_segments where segment_type = 'LOBSEGMENT';" | sql -p lab-vm151...) (ctrl+o to
expand)
I will check if there are other tables starting with 'WR' that contain data in the schema.
● Bash(echo "select table_name, num_rows from user_tables where table_name like 'WR%' and num_rows > 0 order by num_rows desc;" | sql ...) (ctrl+o to
expand)
I will check when the statistics were last gathered for the custom tables.
● Bash(echo "select table_name, last_analyzed from user_tables where table_name not like 'WR%' order by table_name;" | sql -p lab-vm15...) (ctrl+o to
expand)
I will check the list of all database users (schemas) to see if there are other relevant schemas in this database.
● Bash(echo "select username from all_users order by username;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will filter the list of database users to identify any non-system user accounts in the database.
● Bash(echo "select username from all_users where username not in ('SYS','SYSTEM','ANONYMOUS','APPQOSSYS','AUDSYS','CTXSYS','DBSFWUSER...) (ctrl+o to
expand)
I will query the total count of visible tables in the database grouped by their schema owner, to see if we have access to tables in other schemas like
POLLO_EBS or TPCC .
● Bash(echo "select owner, count(*) from all_tables group by owner order by count(*) desc;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will wait for the background query on table counts by owner to complete.
I will check if there are database links or directories defined in the database that our user has access to.
● Bash(echo "select db_link, username, host from all_db_links; select owner, directory_name, directory_path from all_directories;" | s...) (ctrl+o to
expand)
I will check the directory objects defined in the database.
● Bash(echo "select owner, directory_name, directory_path from all_directories;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will check the Oracle Database version details.
● Bash(echo "select banner from v$version;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will query product_component_version to see if we have access to get the version info that way.
● Bash(echo "select * from product_component_version;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
▸ Thought for 19s, 1.0k tokens
Confirming Key Details
I will generate a database investigation report as a markdown artifact ( database_investigation_report.md ) summarizing these details for your
convenience.
● Create(/home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/database_investigation_report.md) (ctrl+o to expand)
I will clean up the temporary schema files from the home directory to keep the workspace clean.
● Bash(rm -f /home/gemini/schema_all.md /home/gemini/schema.csv) (ctrl+o to expand)
我已經對您的 Lab Oracle 資料庫完成初步調查,並將完整的分析結果彙整至這份報告:
👉 database_investigation_report.md
### 💡 關鍵摘要:
1. 資料庫版本:Oracle Database 19c Enterprise Edition (19.3.0.0.0)。
2. 主要資料表:共發現 7 張主要自訂資料表(與動畫評分與政府資料集相關),其中資料量最大的是 USER_FILTERED (高達 1.09 億筆資料,約 2.06 GB)與
FINAL_ANIMEDATASET (約 3,263 萬筆資料,約 8.13 GB)。
3. ⚠️ 效能警訊:這三個最大的資料表( USER_FILTERED 、 FINAL_ANIMEDATASET 、 USERS_SCORE_2023
)目前完全沒有建立任何索引(Index)或條件約束。如果在此時對這些資料表進行查詢或關聯(Join),會引發全表掃描(Full Table Scan),導致嚴重的效能問題。
### 接下來您可以:
• 讓我協助您為常用查詢欄位建立索引以提升效能。
• 針對特定資料表進行更深入的資料內容抽樣與查詢。
請問您接下來希望進行哪一項調整或調查?
────────────────────────────────────────────────────────────
> 幫我找出這些 table 的關聯,清單如下
DESC ANIME_DATASET_2023;
DESC ANIME_FILTERED;
DESC FINAL_ANIMEDATASET;
DESC GOV_DATASET_REGISTRY;
DESC USERS_DETAILS_2023;
DESC USERS_SCORE_2023;
DESC USER_FILTERED;
▸ Thought for 3s, 1.1k tokens
Mapping Data Relationships
I will run queries to verify the logical relationships (common keys and data overlap) between the user tables and the anime tables.
● Bash(echo "select count(*) from users_details_2023 d where d.mal_id in (select distinct user_id from user_filtered where rownum <= 1...) (ctrl+o to
expand)
I will check if the usernames in the user details table match the usernames in the user score table.
● Bash(echo "select count(*) from users_details_2023 d join users_score_2023 s on d.username = s.username where rownum <= 100;" | sql ...) (ctrl+o to
expand)
I will wait for the query to check username overlaps to complete.
I will terminate the running join query task to avoid resource waste, as it is performing an unindexed join on millions of records which takes too
long to execute.
● ManageTask() (ctrl+o to expand)
▸ Thought for 2s
Analyzing Query Results
────────────────────────────────────────────────────────────
> 其實你可以在 sql 工具直接直性下列語法
I will execute the DESC command in the sql console for one of the tables to see if it supports the description syntax.
● Bash(echo "DESC ANIME_DATASET_2023;" | sql -p lab-vm151-oracle19c-pollo) (ctrl+o to expand)
I will write a python script to execute the DESC command for each of the 7 tables and write the results to a single markdown file, so we can see all
of them in detail.
● Create(/home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/scratch/run_desc.py) (ctrl+o to expand)
I will run the description script to gather all schema information.
● Bash(python3 /home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/scratch/run_desc.py) (ctrl+o to expand)
I will view the description file /home/gemini/desc_all.md to see the results.
● Read(/home/gemini/desc_all.md) (ctrl+o to expand)
▸ Thought for 2s, 1.2k tokens
Analyzing Relationships
I will clean up the temporary /home/gemini/desc_all.md file since we have extracted all the information.
● Bash(rm -f /home/gemini/desc_all.md) (ctrl+o to expand)
I will create a database relationships report as a markdown artifact ( database_relationships_report.md ) with a Mermaid Entity-Relationship Diagram
(ERD) and explain the joins and logical keys.
● Create(/home/gemini/.gemini/antigravity-cli/brain/e0c44670-f6ca-49e2-97d3-43ecd5e97ff4/database_relationships_report.md) (ctrl+o to expand)
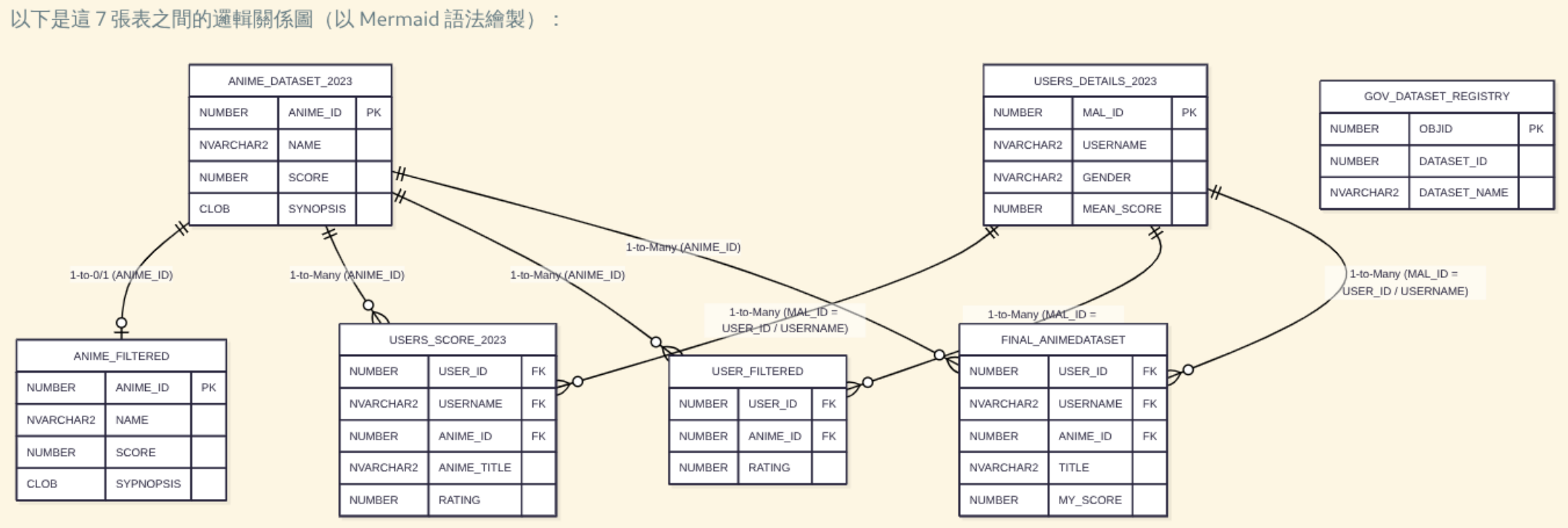
我已經成功為您解析了這 7 張自訂資料表之間的邏輯關聯,並建立了一份詳細的關聯與關係圖(ERD)報告:
👉 database_relationships_report.md
### 📌 關係核心摘要:
1. 動畫主檔:以 ANIME_ID 為主鍵(PK), ANIME_DATASET_2023 是完整版, ANIME_FILTERED 是篩選後的子集。
2. 使用者主檔:以 MAL_ID 為主鍵(PK)、 USERNAME 為唯一名稱,儲存在 USERS_DETAILS_2023 。
3. 評分關聯(多對多): USER_FILTERED (1.09 億筆)、 FINAL_ANIMEDATASET (3,263 萬筆) 與 USERS_SCORE_2023 (2,432 萬筆) 皆作為關聯表,藉由 USER_ID /
USERNAME 對應使用者, ANIME_ID 對應動畫。
4. 孤立資料表: GOV_DATASET_REGISTRY 儲存政府資料集資訊,與上述動畫/使用者系統完全獨立,沒有任何邏輯關聯。
有關詳細的實體關係圖(Mermaid ERD)與 Join SQL 語法範例,您可以隨時點選 database_relationships_report.md 查看。
請問接下來您需要針對特定資料表進行查詢測試,或是為大表的關聯欄位建立索引以進行優化呢?
|